Khi web app của bạn đang ở giai đoạn nhi đồng dễ bảo thì mọi thứ bạn hoàn toàn có thể kiểm soát bằng cơm nhưng một khi app của bạn trở nên khó bảo thì đó là lúc bạn cần monitoring. Làm sao để biết được toàn cảnh hành vi hay perfomance của hệ thống của bạn có đang chạy đúng như bạn mong muốn không.
Việc monitoring trong Elixir application cũng có một lợi thế nữa là bạn có thể sử dụng khá nhiều tools từ Erlang đã có sẵn trước đó để áp dụng vào hệ thống của mình.
Stack
Có rất nhiều stack hiện nay có thể áp dụng cho nhiều loại hệ thống khác nhau nhưng để cho khởi đầu đơn giản thì tôi chọn sử dụng Influxdb cho time-series database, Telegraf làm agent cho việc pull metrics và Grafana cho việc visualizing metrics.

Time-series database
Về lợi thế thì InfluxDB có những gì?
- Timestamps optimization
- High writes, high query loads
- Strong SQL-like query language
- Index theo tags, rất nhanh và thuận tiện cho việc query
- Cung cấp api đơn giản thông qua http hoặc udp hoặc giao thức riêng của InfluxDB -
line protocol - ...etc
Bạn có thể đọc thêm documentations của InfluxDB để hiểu rõ hơn về time-series database này.
Collecting and Reporting metrics
Bạn đã có database rồi. Giờ sao. Làm sao để collect metrics? Ở đây tôi sử dụng Telegraf để pull metrics từ các services. Telegraf là một pluginable agent có thể collect inputs từ rất nhiều nguồn khác nhau (K có đếm cơ mà đâu đó tầm 150 sources) và gửi đến các outputs mà bạn có thể chỉ định. Ví dụ output ở đây có thể là InfluxDB.
[agent]
interval = "10s"
round_interval = true
metric_batch_size = 1000
metric_buffer_limit = 10000
collection_jitter = "0s"
flush_interval = "10s"
flush_jitter = "0s"
precision = ""
debug = false
quiet = false
hostname = ""
omit_hostname = false
[[outputs.influxdb]]
urls = ["http://influxdb:8086"]
database = "telegraf"
retention_policy = ""
write_consistency = "any"
timeout = "5s"
# Read metrics about cpu usage
[[inputs.cpu]]
# Read metrics about disk usage by mount point
[[inputs.disk]]
# Read metrics about disk IO by device
[[inputs.diskio]]
# Get kernel statistics from /proc/stat
[[inputs.kernel]]
# Read metrics about memory usage
[[inputs.mem]]
# Get the number of processes and group them by status
[[inputs.processes]]
# Read metrics about swap memory usage
[[inputs.swap]]
# Read metrics about system load & uptime
[[inputs.system]]
[[inputs.socket_listener]]
service_address = "udp://:8092"
data_format = "influx"
[[inputs.rabbitmq]]
url = "http://rabbitmq-1:15672"
name = "rmq-server-1" # optional tag
username = "$R_USERNAME"
password = "$R_PASSWORD"
Trên đây là một config cơ bản giúp bạn có thể pull metrics từ các nhiều nguồn khác nhau. Gởi các thông tin như mem, disk, cpu, rabbitmq overview,... tới outputs theo khoảng thời gian interval mà bạn có thể đặt trước. Điều này giúp bạn có thể tránh việc network traffic tăng cao hay việc writes data xuống InfluxDB quá nhiều trong một thời điểm. Vì vậy bạn có thể đặt Telegraf đứng giữa Application và database trong trường hợp bạn collect metrics từ app với số lượng lớn một cách liên tục. Trong trường hợp bạn muốn kéo metrics từ nhiều services khác nhau, bạn nên chạy nhiều telegraf daemons khác nhau để có thể cài đặt inputs-outputs cho phù hợp.
Elixir application metrics
Driver
Về driver cho InfluxDB thì tui có sử dụng Fluxter giúp tạo connections pool tới InfluxDB/Telegraf. Api thì cũng rất đơn giản.
Đầu tiên bạn cần define module sẽ sử dụng fluxter behavior:
defmodule MyApp.Fluxter do
use Fluxter
end
def start(_type, _args) do
children = [
MyApp.Fluxter.child_spec(),
# ...
]
Supervisor.start_link(children, strategy: :one_for_one)
end
Config để kết nối tới metrics collector
config :fluxter, MyApp.Fluxter,
host: System.get_env("TELEGRAF_HOST") || "web-telegraf",
port: String.to_integer(System.get_env("TELEGRAF_PORT") || "8092"),
pool_size: 10
Xong! Giờ thì bạn có thể report metrics với Fluxter
def do_something() do
MyApp.Fluxter.write("something_done", [func: "do_something"], 1)
Myapp.Fluxter.measure("func_exec_time", [func: "another_func"], &another_func/0)
end
Ví dụ bạn có thể collect request time của tất cả các request tới application:
defmodule MyApp.Plug.EuMetrics do
@time_unit :milli_seconds
def init(opts), do: opts
def call(conn, _) do
start_time = :erlang.monotonic_time(@time_unit)
Plug.Conn.register_before_send(conn, fn conn ->
end_time = :erlang.monotonic_time(@time_unit)
MyApp.Fluxter.write(
"request_time",
[type: "render_req"],
value: (end_time - start_time) / 1
)
conn
end)
end
end
hay measuring Ecto
defmodule MyApp.Repo do
use Ecto.Repo, otp_app: :myapp
def log(entry) do
MyApp.Fluxter.write(
"query_exec_time",
[],
(entry.query_time + entry.queue_time || 0) / 1000
)
super(entry)
end
end
##Erlang VM stats
vmstats là một erlang application tổng hợp metrics từ erlang vm rồi gửi chúng tới một configurable sink
config :vmstats,
sink: MyApp.Fluxter,
sched_time: true,
base_key: "vmstats",
key_seperator: ".",
# in ms
interval: 1000,
memory_metrics: [
{:total, :total},
{:processes_used, :procs_used},
{:atom_used, :atom_used},
{:binary, :binary},
{:ets, :ets}
]
vmstats yêu cầu chúng ta phải implement vmstats_sink behavior và may thay Fluxter pool có thể được sử dụng như là một vmstats sink
defmodule MyApp.Fluxter do
use Fluxter
@behaviour :vmstats_sink
def collect(_type, name, value) do
write(name, value: value)
end
end
Ok vậy là cài đặt xong, vmtats giúp chúng ta collect những loại metrics gì? ETS tables, atoms, processes, binaries và total memory, number of process, process limit, garbage collection count,..
Visualizing metrics
Việc hiện thị metrics thì mình sử dụng Grafana. Grafana là 1 open-source cung cấp giao diện trực quan support các nguồn dữ liệu và plugins khác nhau và Grafana support InfluxDB. Sau tất cả chúng ta có thể có một dashboard kiểu như thế này:

Bạn chỉ cần cài đặt datasource đúng kiểu rồi có thể query data rất dễ dàng:

Alerting
Thực ra trọng bộ TICK stack còn có 1 component tên là Kapacitor - Realtime data process streaming có nhiệm vụ process data và trigger action dựa trên kết quả trả về. (VD như Kapacitor sẽ kéo cpu measurement về nếu như quá ngưỡng cho phép thì trigger alert). Nhưng hiện tại mình chưa có dùng Kapacitor mà dùng luôn tính năng alerting của Grafana.
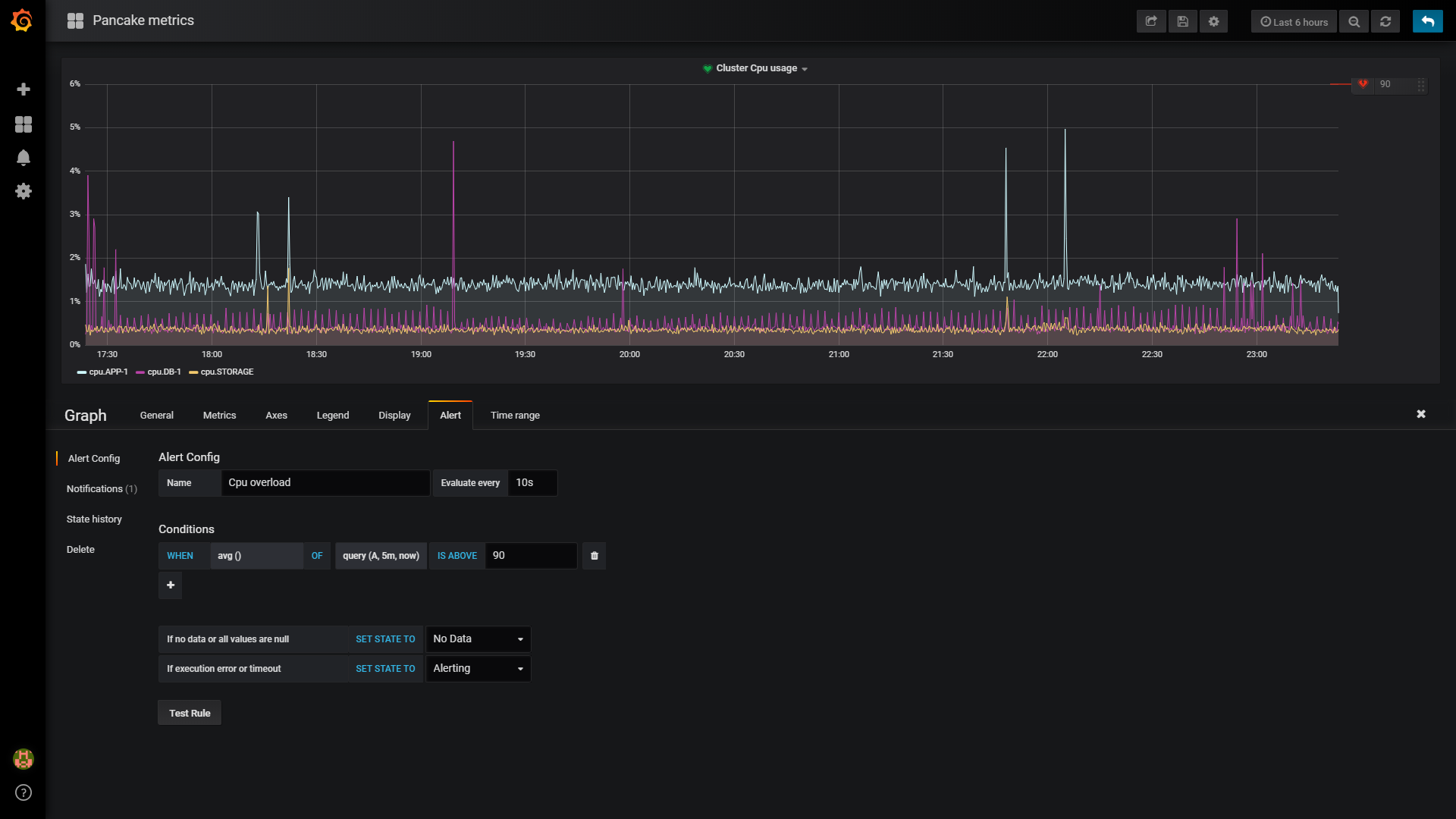
Như vậy là mình có thể bật notification channel alerting trên slack rồi yên tâm nằm ngủ rồi.
Tổng kết
Sau khi nhận thấy application của mình ngày càng khó quản lý bằng cơm. Cuối cùng tôi cũng phải build một hệ thống monitoring riêng cho mình. Tuy đơn giản nhưng hiệu quả mang lại là rất cao. Cũng vì muốn các bạn chưa từng build một monitoring service nào có thể có một chút view về vấn đề này. Nên tôi viết bài này với hy vọng những bạn đang mò mẫm như tôi lúc mới bắt đầu làm có thể có những solutions cho riêng mình.